Evaluation Metric (1) - Confusion Matrix, Accuracy, Precision, Recall, F1-Score
이 세상 모든 평가 지표가 accuracy 였으면 좋겠다..
이번 포스팅에서는 볼 때마다 햇갈리는 Confusion matrix에 대해서 정리하도록 하겠습니다. 분류 문제를 풀게되면 모델의 성능을 평가하기 위해서 Accuracy로 모델의 정확도를 평가하게 됩니다. 하지만 데이터의 라벨이 불균형하다면 Accuracy 만으로 모델의 성능을 평가하기 어렵습니다.
예를들면, Kaggle의 Credit Card Fraud Detection 문제에서는 284,807개의 데이터 중에서 사기 데이터는 492개 밖에 되지 않습니다. 모델에게 normal data와 fraud data를 분류하는 문제를 시키게 되면 모델은 normal data만 무조건 찍게되어도 Accuracy가 99.82%가 나옵니다.
이 때, 사용할 수 있는 평가지표로 Precision과 Recall이 있습니다. Precision과 Recall을 설명하기에 앞서서 쉽게 이해하기 위한 Confusion Matrix를 살펴보겠습니다.
Confusion Matrix
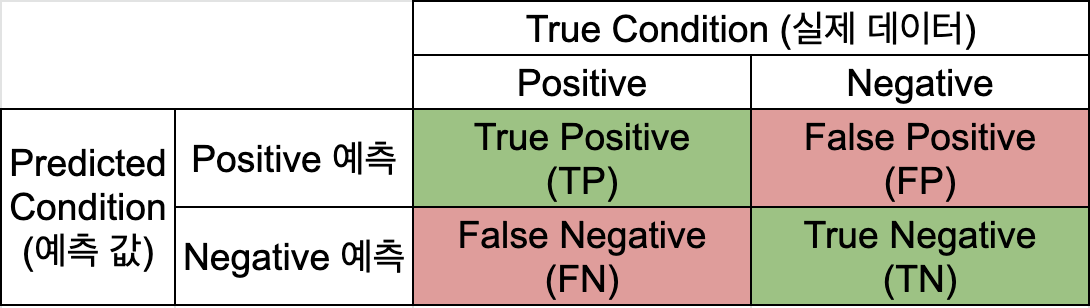
위 그림에서 보는 것처럼 실제 데이터의 라벨과 모델이 예측한 라벨을 비교하는 표가 Confusion Matrix 입니다. 위 표를 기준으로 Accuracy, Precision, Recall을 모두 계산할 수 있습니다.
Accuracy
Accuracy는 정확도로 전체 샘플 중에 정답을 맞춘 개수를 의미한다. 일반적으로 분류모델에서 가장 많이 쓰이는 평가 지표이고, 쉽게 이해할 수 있다는 장점이 있습니다.
\[Accuacy = \frac{TP+TN}{TP+FP+FN+TN}\]Precision
Precision은 정밀도로 Positive라고 예측한 것 중에서 실제로 Positive인 것에 대한 비율입니다. Fraud Detection 문제라고 보면 모델이 Fraud라고 예측한 것 중에서 실제로 Fraud 인 경우 입니다. 즉, 모델이 예측을 얼마나 정밀하게 했는지(?) 라고 생각하면 됩니다.
\[Precision = \frac{TP}{TP+FP}\]Recall
Recall은 재현율로 실제 Positive 데이터 중에서 모델이 Positive로 예측한 것에 대한 비율입니다. Fraud Detection 문제라고 보면 실제 Fraud 데이터 중에서 모델이 Fraud라고 예측한 경우 입니다. 즉, 모델이 Fraud를 얼마나 잘 재현했는지(?)라고 생각하면 됩니다.
\[Recall = \frac{TP}{TP+FN}\]위의 세 개 식 중에서 Accuracy는 자체로서 평가의 기준이 될 수 있지만, Precision이나 Recall은 모델 평가의 관점에 따라서 다르게 해석되거나 사용될 여지가 있습니다.
예를 들면, Recall은 99%가 나오고 Precision은 10%가 나온 경우를 생각해볼 수 있습니다. 얼핏 생각해보면 Recall이 높기 때문에 모델은 Fraud Detection 문제에서 모든 Fraud를 맞췄습니다. 하지만, 실제 모델을 사용하는 사람 입장에서는 너무 많은 Fraud 알람이 발생하게 되어서 피곤하고, 실제 Fraud 인지 검증해야하는 피로가 생깁니다.
반대로 Precision이 높고 Recall이 낮은 상황은 애초에 모델의 대부분이 normal 데이터라고 찍어버리면, 보기에는 Precision이 높지만 Fraud 데이터를 놓칠 우려가 있습니다.
이러한 상황을 극복하고자 사용하는 평가 지표가 F1 score 입니다.
F1 score
F1 score는 Precision과 Recall 결과에 대한 조화평균 값으로 Precision과 Recall 결과를 모두 고려할 수 있는 평가 지표입니다.
\[F1-score = \frac{2\times Precision\times Recall}{Precision+Recall}\]Hands on
scikit-learn confusion matrix
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.confusion_matrix.html
sklearn.metrics.confusion_matrix(y_true, y_pred, *, labels=None, sample_weight=None, normalize=None)[source]
>>> import numpy as np
>>> from sklearn.metrics import confusion_matrix
>>> true_label = np.random.choice([0,1], 30)
>>> pred_label = np.random.choice([0,1], 30)
>>> confusion_matrix(true_label, pred_label)
array([[ 7, 10],
[ 5, 8]])
>>> tn, fp, fn, tp = confusion_matrix(true_label, pred_label).ravel()
>>> print(tn, fp, fn, tp) # 주의 : python은 true(1), false(0) 라벨을 0, 1 순서로 array 구성하여 위의 그림과 위치가 다름
7 10 5 8
>>> accuracy = (tp+tn)/(tn+fp+fn+tp)
>>> precision = tp/(tp+fp)
>>> recall = tp(tp+fn)
>>> f1_score = 2*precision*recall/(precision+recall)
>>> print(accuracy, precision, recall, f1_score)
0.5 0.4444444444444444 0.6153846153846154 0.5161290322580646